ISO 27002 “Code of practice for information security controls” list 144 controls with the same structure for all the controls. If one would like to work on these controls, like reusing them in another documentation or doing a presentation etc, then it can be tedious to re-write the text manually into another format. Instead one can try to automate, as much as possible, and process the text of the standard by using a simple script programming language. In this blog, the text is first processed by using autoit script.
The steps
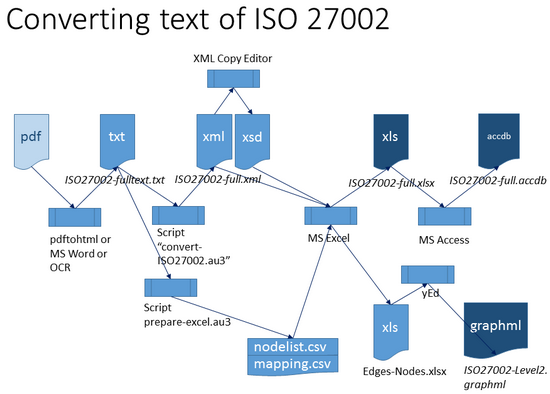
The figure below shows the overview of the steps.
- The input file for processing (with the autoit script) is the text of the ISO 27002 standard.
- The 3 outputs are an excel file and an access database with all the content from those 114 controls, and a picture with the control categories (heading H2 level).
The content of ISO 27002 cannot be reproduced here. But the following files are provided in case if you want to try these things yourself:
The output of the first autoit script is XML file. The structure of this XML file is shown below. This structure is selected because the layout of the ISO 27002 mostly follow this kind of heading and chapter structure. Some manual editing of the txt file is needed to make the input file to follow a consistent structure. This way the same parser code can be used without needing to program exceptions. (ie. fixing the data quality rather than the code).
<iso27002>
<clause>
<clause_title_h1> </clause_title_h1>
<control_category>
<control_category_title_h2> </control_category_title_h2>
<category_objective> </category_objective>
<security_control>
<control_title_h3> </control_title_h3>
<control_text> </control_text>
<implementation_guidance> </implementation_guidance>
<other_information> </other_information>
</security_control> </control_category>
</clause>
</iso27002>
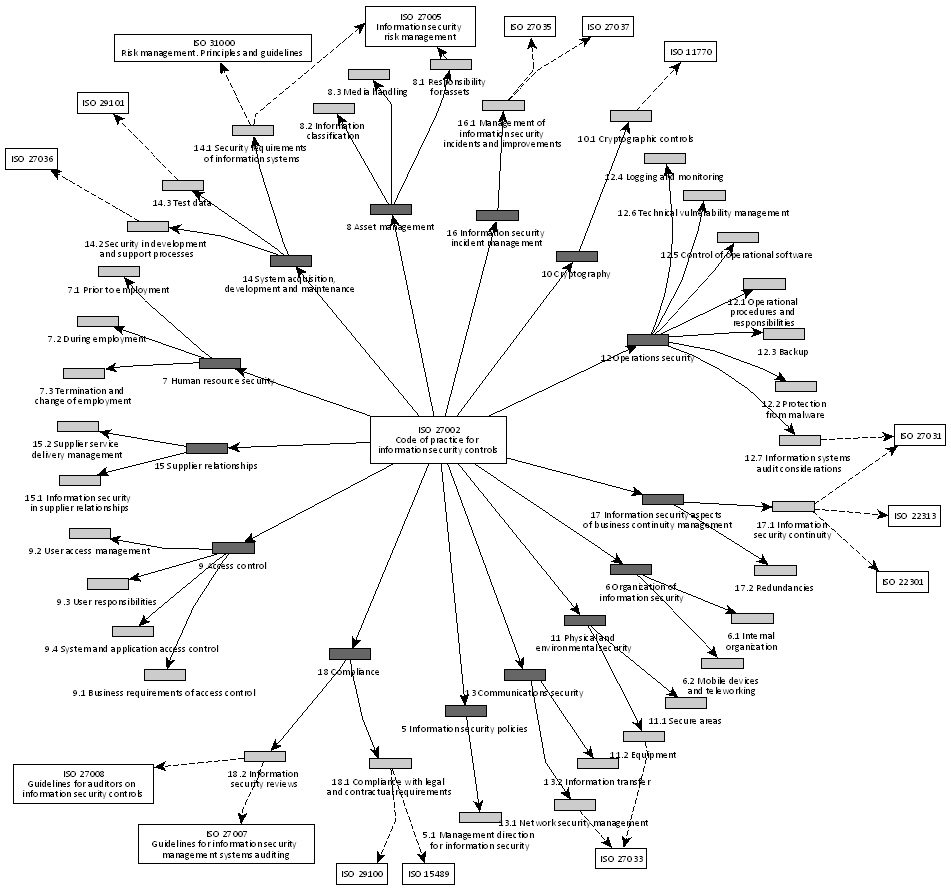
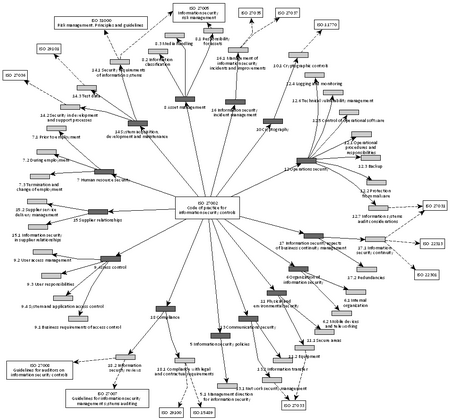
Output 1: the graph (and picture)
The figure below is exported from yEd; after it has been manually beautified 🙂
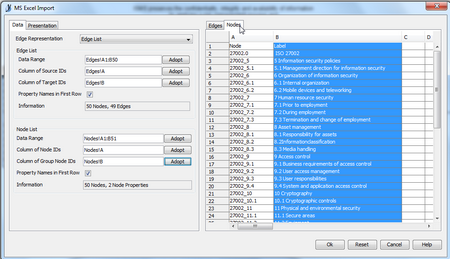
When importing to yEd, one need to map the data for both Edges and Nodes, and also choose the label for the Nodes (in presentation tab).
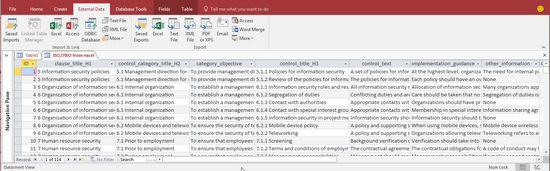
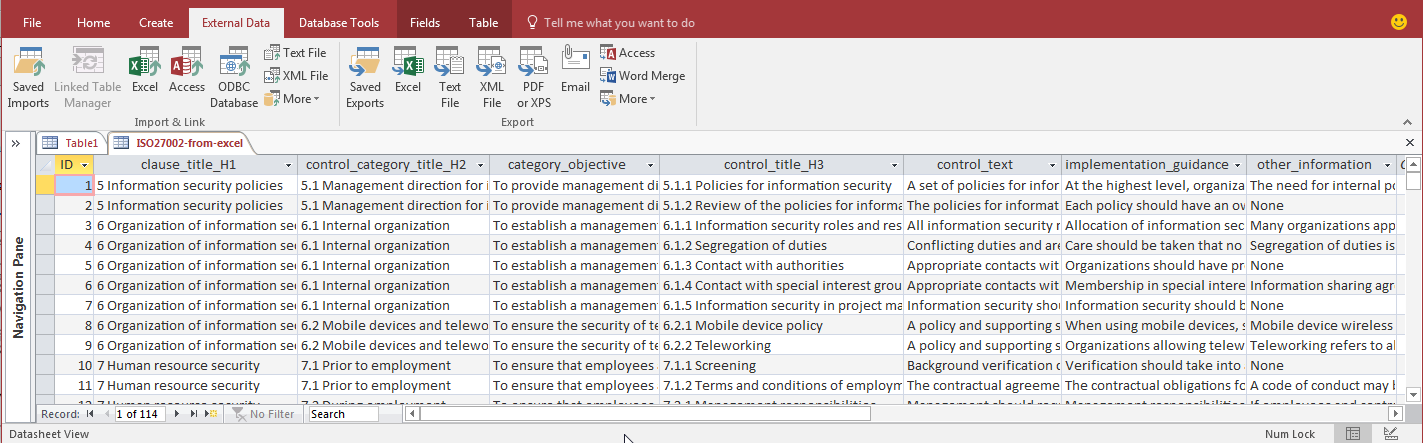
Output 2: the access database
The XML import to excel works well, and the first row contain the data field names. However, it is difficult to browse this manually since some fields are quite long. Therefore one can store the data also into another format, in this case the excel file was imported into an access database. In the basic view mode, one can see the rows with equal spacing and that there are 144 rows (ie. controls).